

Before the Agent Acts 1.0: Building the Foundation for Autonomous Execution
Part of the Deitsch's DREAM Enablement Series: Design Reference for Enterprise AI Maturity

Before the Agent Acts 1.0: Building the Foundation for Autonomous Execution
Part of the Deitsch’s DREAM Enablement Series
Design Reference for Enterprise AI Maturity
David Deitsch
Technology Workflows Architect | AI Strategist
Executive Summary
Everyone wants AI to take action. But few pause to ask: does it even know what it’s acting on?
In the rush to build agentic workflows—self-healing systems, AI-driven automation, real-time response—we often skip the first question an engineer would ask: What are the components? Where do they live? How are they connected? And what are their authoritative states

The DREAM model defines the progression toward execution: Conversation → Suggestion → Execution (https://deits.ch/DREAM). And Stage 2—Suggestion—has emerged as the weak link preventing true autonomy.

So, we face a decision: Either improve the model’s ability to Suggest—or accept that it cannot Suggest, and work around that limitation. Because Execution without Conversation or Suggestion… is just workflow.
Given this, the path forward becomes clear: How do we help AI improve its suggestion capabilities?
This essay introduces three Foundational Data Capabilities every enterprise must strengthen to enable reliable AI-driven suggestions:
Source Data Control – Structured documentation of how things are supposed to work.
Active Data Control – Near real-time, refreshed visibility into how things actually are.
Enterprise Trust (Preview) – A first look at the deeper trust systems required to govern what data the AI should choose, which sources it should prefer—and most importantly, why.
Foundational Capability 1: Source Data Control
In most enterprise environments, the data layer underneath automation is brittle or missing entirely. The Configuration Management Database (CMDB) is incomplete or inaccurate. Data population is delayed or shallow. System relationships are either manually drawn—or not captured at all.
That doesn’t stop the ambition. Teams push forward with AI prototypes, hoping language models can leap over messy data and somehow land on solid ground.
They won’t. AI doesn’t remove the need for system awareness—it amplifies it.
Product documentation, SOPs, CMDB schemas—this is how things are supposed to work. If an AI's Suggestions are built on outdated or fragmented descriptions of the environment, even basic logic can break. This isn’t just about storing documents—it’s about ensuring structured, navigable, and trustworthy representations of expected behavior and configuration.
Take for example this CMDB Schema:
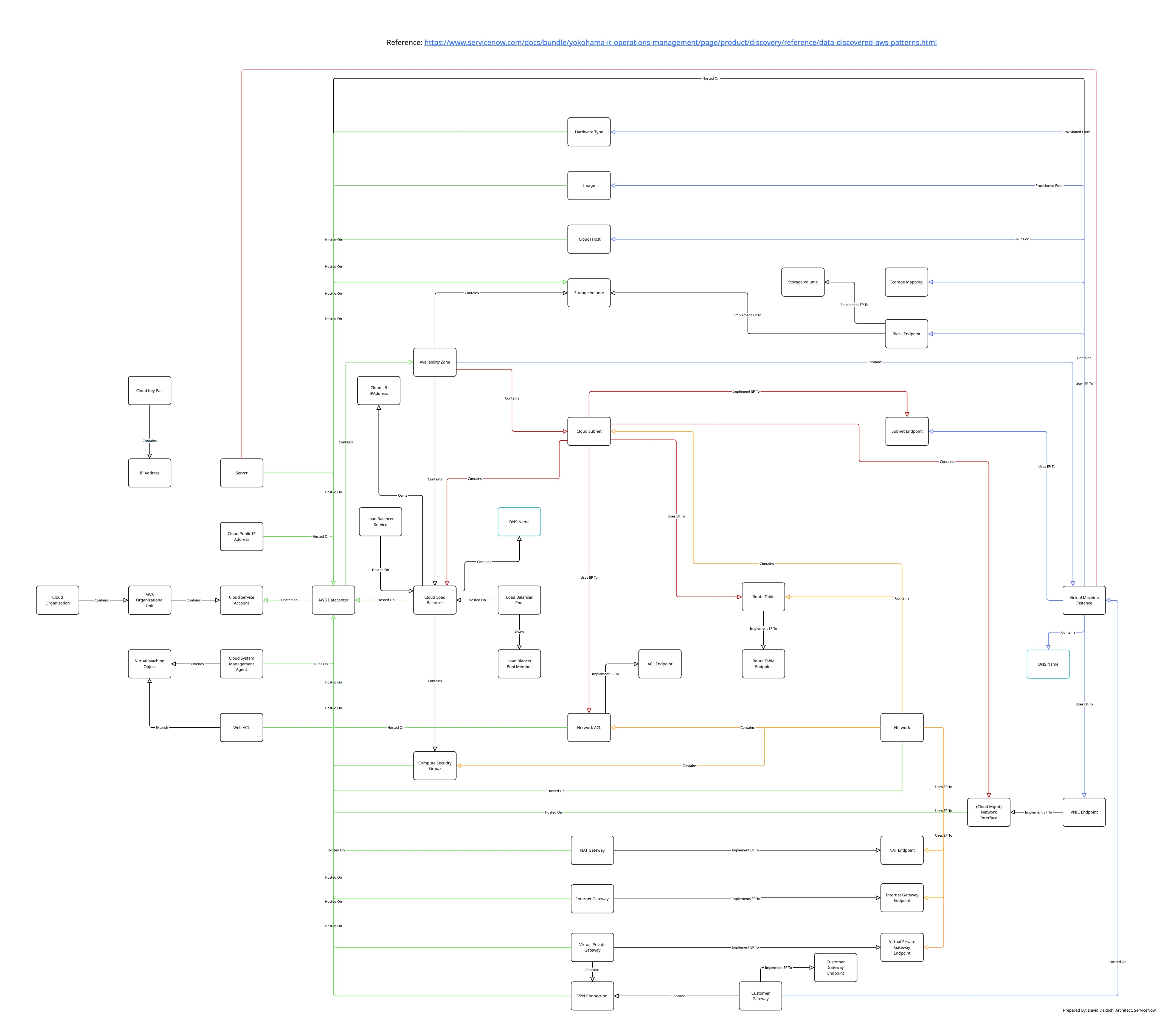
If an AI is expected to serve as a conversational interface, it must deeply understand three things:
English (to engage the user)
The platform’s operational schema (e.g., where credentials and history are stored)
The target schema (e.g., the server, instance, or app the action will affect)
Without this multi-perspective understanding—user, platform, and target—the AI cannot generate accurate Suggestions.
Take Microsoft Copilot. We often assume that because it’s embedded, it understands the application. But, in reality, Copilot cannot even reliably format text inside Word. When asked, it suggests how you might do it, but not how it might do it for you. Why? Likely because it doesn’t understand Word's internal schema—its data model, formatting engine, or interaction boundaries.
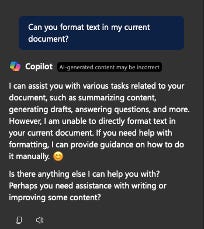
Copilot can read and write English. But that’s not the same as understanding Word.
This translation challenge—between interface, system, and execution context—is where Suggestion often breaks. And in the enterprise, the cost of broken Suggestions is high.
So, the first step is clear:
Enterprises must give their LLMs access to correct, current, and structured source data—across every domain where they expect the model to communicate, interpret, or act.
Foundational Capability 2: Active Data Control
Active data in the enterprise is not one monolithic source—it comes in layers. To make this practical, we can break it into two categories: Data Foundations and Just-In-Time (JIT) Data.
JIT Data takes two common forms:
Streaming into a platform in near real-time
Or retrieved at runtime in response to a specific question the static dataset can't answer alone
In a prior demonstration, we explored this concept using a MAC address to locate a physical device. You can view that example here:

In that scenario, we utilized network MAC address table data—already populating daily into the CMDB—as the active data foundation the agent could search. That worked, because the MAC address belonged to a wired device.
But if the MAC address had belonged to a wireless device, that same strategy may have failed. A Just-In-Time (JIT) query to the wireless controller would have been far more effective.
Daily snapshot data may be sufficient for wired infrastructure. But wireless usage introduces volatility—devices move, disconnect, or roam—which often demands real-time visibility.
Now that we’ve seen both wired and wireless scenarios, let’s step back and extract a more general principle: Active Data Strategies must align with the AI’s three spheres of understanding—user, platform, and target.
To build a reliable Platform Data Foundation, the best starting point is often the platform manufacturer’s own data population mechanism. In my experience, two things tend to hold true:
At scale, buying is cheaper than building
Vendors populate their own schemas substantially better than anyone else
Yes, most tools can extract the data. But the careful, schema-aligned mapping required for AI to understand the system—that level of precision nearly always comes from the manufacturer.
Here’s what Active Data Foundations look like when done right.
In this short video, we walk through the discovery of a full VMware vCenter environment using a platform-native method. The entire process—from scan initiation to populated dependency map—completes in under 30 seconds.
The important part isn’t the tool—it’s the outcome:
98 configuration items
139 relationships
Automatically mapped across ESX servers, virtual machines, ports, and data stores
That’s what it looks like when the platform speaks its own schema fluently.
And that’s what Suggestion needs if it’s ever going to act with confidence.
The real requirements for JIT data are connectivity and contextual depth. In the MAC address example above, the platform needs an integration to the wireless controller—and a way to perform a live lookup that returns the location of the access point currently serving that MAC address.
That same wireless controller may also emit a live event stream about the health and status of its access points. And critically, that’s a completely different integration. One handles on-demand lookup. The other handles streaming events. We should also add to that a third integration—one that likely ran earlier—advising the platform of the existence of the AP and the controller, and how they work together.
As AI platforms grow, they must support the full range of native integrations:
Data Foundation population
JIT real-time lookups
JIT event streams
Without all three, Enterprise AI will remain brittle—asking the right questions, but unable to provide the correct answers.
Foundational Capability 3: Enterprise Trust (Preview)
Most efforts today focus on the first two Foundational Data Capabilities: How do we give an AI access to all the data it requires to perform?
But this third capability—Enterprise Trust—still isn’t getting the attention it deserves. This layer governs what the AI believes—and why.
It determines source reliability, conflict resolution, and authorization signals
It spans both static content (docs, policies) and dynamic inputs (user assertions, logs)
It includes version control, recency weighting, privilege context, and even intent inference
Enterprise Trust is the AI equivalent of chain of command. Without it, Suggestion is just noise.
No matter how complete our data, there will always be conflicts. Static sources will lag behind real-time signals. Documentation will differ from logs. And even when both align—what happens when I, the operator, say:
“I know you’re supposed to shut it down at 85%, but today… let it go to 90.”
Am I a trusted engineer who knows exactly what I’m doing?
Or am I a threat actor?
And how does the AI decide?
That’s the final gate between Suggestion and Execution.
We’ll be expanding on this in the future—because it’s that important. But it also belongs here, in outline form.
Because if you don’t solve for trust, no matter how good your data is, your agents will never be able to use it correctly.
Conclusion
Everyone wants agents that can act. But the truth is—most enterprises are not yet ready for autonomous execution.
They’re still trying to answer a more fundamental question: How do we help AI suggest well enough to act at all?
The DREAM model makes this gap visible.
Execution only works when Suggestion is reliable. And Suggestion only works when grounded in:
Structured source data
Refreshed, real-time context
A working system of trust
These are not abstract ideals. They’re buildable layers—capabilities that can be strengthened.
The first two—Source Data Control and Active Data Control—are already receiving investment.
The third— Enterprise Trust—is only beginning to be understood. But it may prove to be the most important of all.
Because if we want AI to move forward with confidence, we must first ensure it knows what to believe—and why.
That’s the real work before the agent acts.
This post accompanies the official v1.0 release of the DREAM framework. Future revisions will be tracked here and in the PDF download.
Download Before the Agent Acts v1.0: Building the Foundation for Autonomous Execution PDF - Part of the Deitsch’s DREAM Enablement Series (Design Reference for Enterprise AI Maturity)
Around here, however, we don't look backwards for very long. We keep moving forward, opening up new doors and doing new things, because we're curious...and curiosity keeps leading us down new paths. - Walt Disney (attributed)